前言
索引(Index)是数据库优化中的最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数的SQL性能问题。索引用于快速找出在某个列中含有某一特定值的行,如果没有索引,那么查询时必须从第1条记录开始,然后读完整个表,直到找出相关的行。在没有索引的情况下,表越大,查询花费的时间就越长。
索引在MySQL中也称为**键(Key)**,是存储引擎用于快速找到记录的一种数据结构。索引具有以下几个优点:
(1)索引大大减少了服务器需要扫描的数据量。
(2)索引可以帮助服务器避免排序和临时表。
(3)索引可以将随机I/O变为顺序I/O。
1. MySQL中的索引分类
MySQL的所有列类型都可以被索引。MyISAM和InnoDB类型的表默认创建的都是BTREE索引;MEMEORY类型的表默认使用HASH索引,但也支持BTREE索引;空间列类型的索引使用RTREE(空间索引)。
MySQL中的索引是在存储引擎层中实现的,而不是在服务器层实现的。索引每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型。MySQL目前提供了以下的几种索引:
| 类型 | 说明 |
|---|---|
| BTREE索引 | 最常用的索引类型,大部分引擎都支持BTREE所以,例如MyISAM、 InnoDB、MEMORY等。 |
| HASH索引 | 只有MEMORY和NDB引擎支持,适用于简单场景。 |
| RTREE索引 (空间索引) |
空间索引是MyISAM的一个特殊索引类型,主要用于地理空间数据类型, 通常使用较少。 |
| FULLTEXT (全文索引) |
全文索引也是MyISAM的一个特殊索引类型,主要用于对全文的索引。 InnoDB从MySQL5.6版本开始,也提供了对全文索引的支持。 |
MySQL目前还不支持函数索引,但是支持前缀索引,即对索引字段的前N个字符创建索引,这个特性可以大大缩小索引文件的大小,从而提高性能。但是,前缀索引在排序ORDER BY和分组GROUP BY操作的时候无法使用,也无法使用前缀索引做覆盖扫描。
2. MySQL中索引的使用原则
首先,选择索引的最终目的是使得查询的速度变快。下面是创建索引时应符合的一些基本原则:
(1)最适合索引的列是出现在WHERE子句中的列,或者连接子句中指定的列,而不是出现在SELECT关键字后的选择列表中的列。
(2)使用唯一索引。考虑某列中值的分布,索引的列的基数越大,索引的效果越好。唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。通常主键上的索引就是唯一索引。
(3)使用短索引。如果对字符串列进行索引,那么应该指定一个前缀长度。较小的索引设计的磁盘I/O较少,较短的值比较起来也更快。更重要的是,对于较短的键值,索引高速缓存(内存)中的块能容纳更多的键值。
(4)利用最左前缀。在创建一个N列的索引时,实际上创建了MySQL可利用的N个索引。多列索引可以起到多个索引的作用,因为可利用索引中的最左边的列集来匹配行,这样的列集被称为最左匹配(Leftmost Prefixing)。
(5)不要过渡索引。索引并不是越多越好,因为每个索引都要占用额外的磁盘空间,并降低写操作的性能,增加维护成本。在修改表的内容时,索引必须进行更新,有时也可能需要重构,因此索引越多,维护索引所花的时间也就越长。此外,MySQL在生成一个执行计划时,要考虑各个索引,这也要花费时间,创建多余的索引还会给查询优化带来了更多的工作。
(6)对于InnoDB类型的表,记录默认按照一定的顺序保存。如果有明确定义的主键,那么按照主键顺序保存;如果没有主键,但是有唯一索引,那么按照唯一索引的顺序保存;如果既没有主键又没有唯一索引,那么表中会自动生成一个内部列,按照这个列的顺序保存。按照主键或内部列进行的访问是最快的,所以InnoDB表尽量自己指定主键,如果有多列都是唯一的,应选择最常访问条件的列作为主键。另外,InnoDB表的普通索引都会保存主键的值,所以主键要尽可能选择较短的数据类型,可以有效地减少索引的磁盘占用,提供索引的缓存效果。
(7)为经常需要排序、分组和联合操作的字段建立索引。经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
(8)尽量使用数据量少的索引。如果索引的值很长,那么查询的速度会收到影响。例如,对一个CHAR(100)类型的字段进行全文检索需要的时间肯定要比对CHAR(10)类型的字段进行全文检索需要的时间更多。
(9)尽量使用前缀来索引。如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段前面的若干个字符,这样可以提高检索速度。
(10)删除不再使用或者很少使用的索引。表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。这时就应该删除这些索引,从而减少索引对更新操作的影响。
3. 什么是覆盖索引?
如果说一个索引包含(或者说覆盖了)所有满足查询所需的数据,那么就称这类索引为覆盖索引(Convering Index)。索引覆盖查询不需要回表操作。在MySQL中,可以通过使用explain命令输出的Extra列来判断是否使用了索引覆盖查询。若使用了索引覆盖查询,则Extra列包含“Using Index”字符串。MySQL查询优化器在执行查询前会先判断是否有一个索引能执行覆盖查询。
覆盖索引能够有效地提高查询到性能,因为覆盖索引只需要读取索引而不需要再回表读取数据。覆盖索引有以下几个优点:
(1)索引项通常比记录要小,所以MySQL会访问更少的数据。
(2)索引都按值的大小顺序存储,相对于随机访问记录,需要更少的I/O。
(3)大多数据引擎能更好地缓存索引,比如MyISAM值缓存索引。
(4)覆盖索引对于InnoDB表尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引中包含查询所需的数据,那么就不在需要在聚集索引中查找了。
下面例子中的SQL语句就使用了覆盖索引:1
2
3
4
5
6
7
8
9mysql> explain select host, user from mysql.user where user='lhr';
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | user | NULL | index | NULL | PRIMARY | 276 | NULL | 4 | 25.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
mysql>
4. 什么是BTREE索引?
BTREE索引是MySQL中使用最为频繁的索引类型,除了Archive存储引擎之外的其他所有的存储引擎都支持BTREE索引。注意此处的BTREE全称是Balance Tree,而不是Binary Tree。实际上,在其他的很多数据库管理系统中BTREE索引也同样是作为最主要的索引类型,这主要是因为BTREE索引的存储结构在数据库的数据检索中有非常优异的表现。在MySQL中,BTREE索引实际使用的存储结构是B+Tree(即B-Tree的变种)。下面就来详细介绍B-Tree和B+Tree。
4.1 B-Tree
B-Tree是一种多叉的平衡搜索树,具备下列两个特性:
(1)平衡性,含有N个结点的B-Tree 高度为O(lgN) 。它的严格高度可能比红黑树(不严格的平衡二叉树)的高度要小许多,这是因为它的分支因子,也就是表示高度的对数的底数可以非常大。
(2)排序性,结点的排列方式类似于二叉搜索树,可以有序的遍历输出结点。
B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子节点到根节点的距离相同,其中每个节点都是一个二元数组[key, data],并且所有节点都可以存储数据。key为索引key,data为除key之外的数据。B-Tree的结构如下图所示:
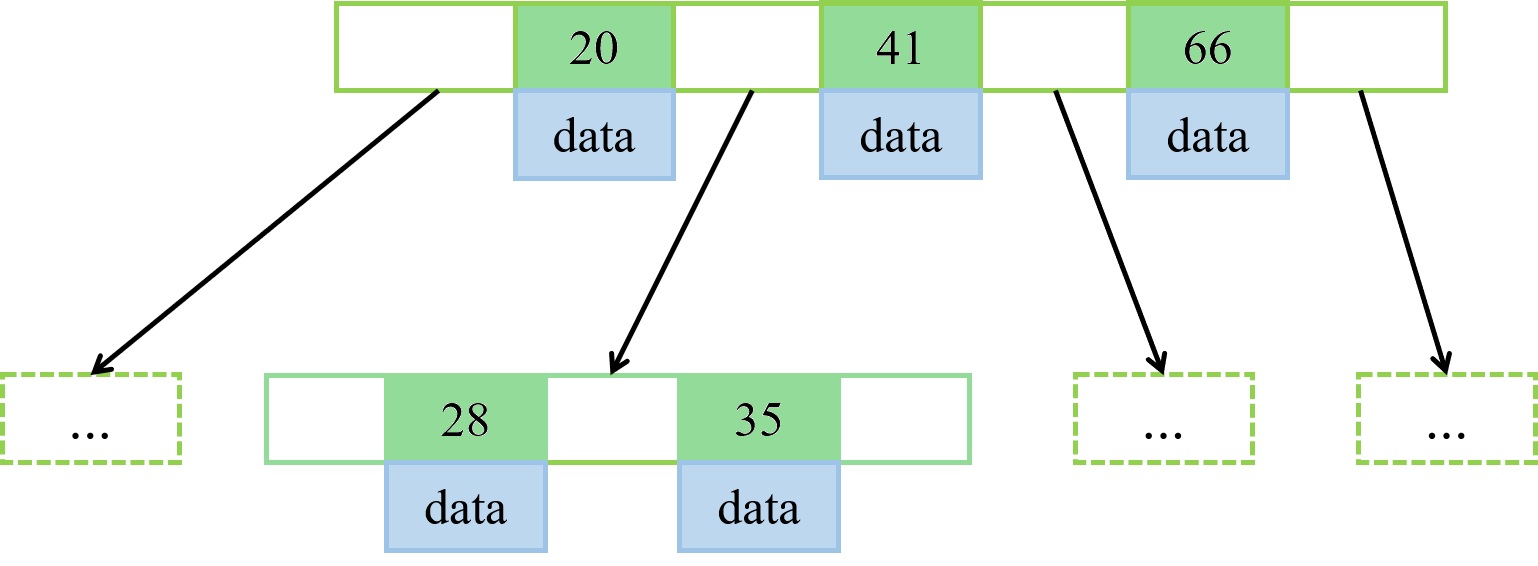
B-Tree的检索原理:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或未找到节点返回null指针。
B-Tree的缺点:
(1)插入或删除数据记录会破坏B-Tree的性质,因此在插入或删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质,从而造成IO操作频繁。
(2)区间查找可能需要返回上层节点重复遍历,同样使得IO操作繁琐。
4.2 B+Tree
B+Tree是B-Tree的变种,主要有以下不同点:非叶子节点不存储data,只存储索引key;只有叶子节点才存储data。叶子结点均在同一层,且叶子结点之间类似于链表结构,即有指针指向下一个叶子结点。B+Tree的结构如下图所示:
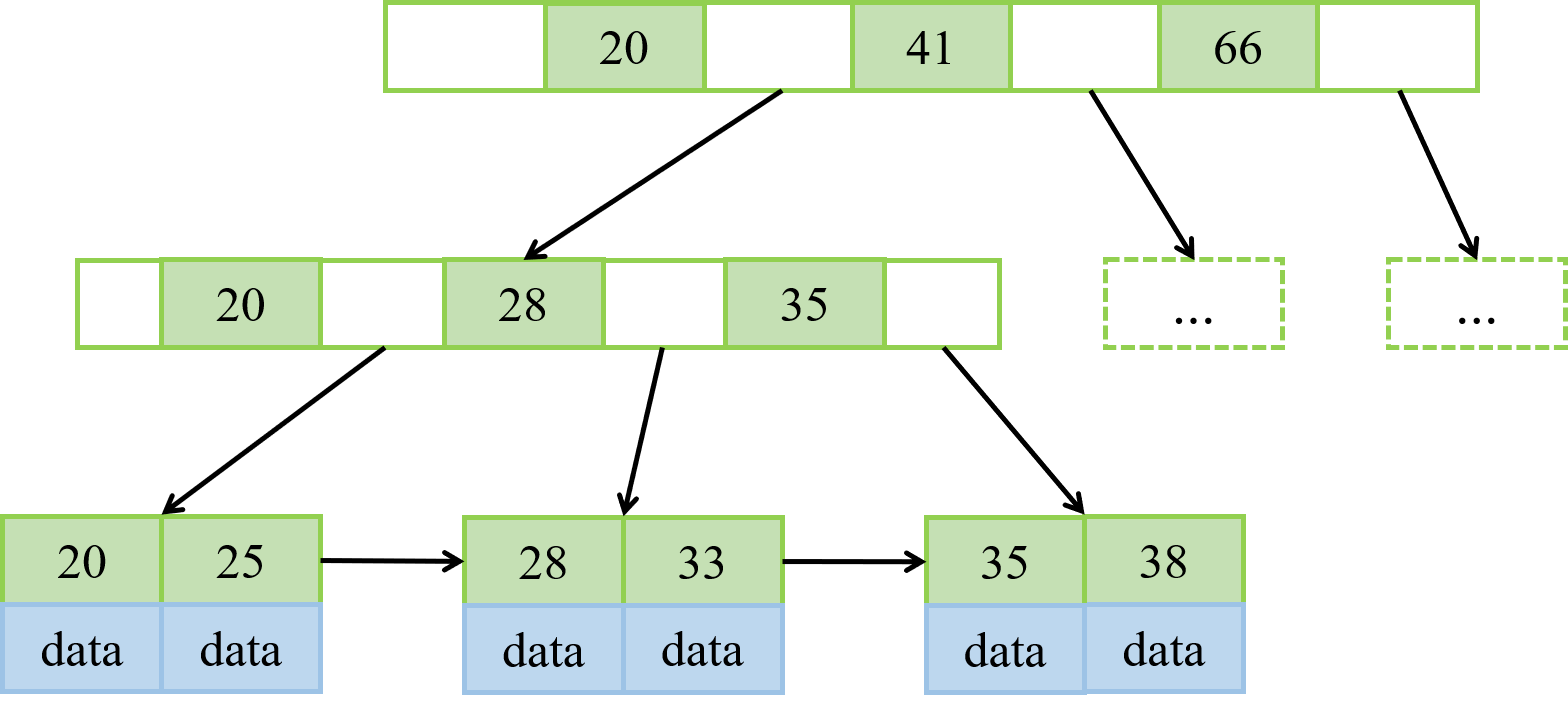
在B+Tree进行单个节点查询时,从根节点到叶子节点的搜索效率基本相当,不会出现大幅波动;但是进行范围查询时,只需要查找区间的两个节点,然后顺着节点和指针顺序遍历访问数据即可,这样极大提到了区间查询的效率(因为无需返回上层父节点重复遍历查找从而减少IO操作)。例如:在上图中要查询索引key为25~38的所有数据记录,当找到25节点后,只需顺着指针一次遍历直到找到38节点即可。
4.3 MySQL为什么选择B+Tree而不是B-Tree作为索引的存储结构?
(1)MySQL利用了磁盘预读原理,将一个B+Tree节点大小设为一个页大小,在新建节点时直接申请一个页的空间,这样就能保证一个节点物理上存储在一个页里,加之计算机存储分配都是按页对齐的,这样就实现了每个节点只需要一次I/O操作(尽量减少IO次数)。
(2)B+Tree相对于B-Tree每个非叶子节点能够存储的索引key更多,树的高度更低,从而能够在存储大量数据情况下,进行较少的磁盘IO。
(3)B+Tree只在叶子节点存储数据,所有叶子结点包含一个链指针,其他非叶子节点只存储索引数据。只利用索引快速定位数据索引范围,先定位索引再通过索引高效快速定位数据。
总的来说,B+Tree层级更少(高度更低),查询速度更稳定,天然具备排序功能,全节点遍历更快。
5. 什么是哈希索引?
哈希索引(Hash Index)建立在哈希表的基础上,它只对使用了索引中的每一列的精确查找有用。对于每一行,存储引擎计算出了被索引的哈希码(Hash Code),它是一个较小的值,并且有可能和其他行的哈希码不同。它把哈希码保存到索引中,并且保存了一个指向哈希表中的每一行的指针。如果多个值有相同的哈希码,那么索引就会把行指针以链表的方式保存在哈希表的同一条记录中。
只有MEMORY和NDB两种引擎支持哈希索引,MEMORY引擎默认使用哈希索引,如果多个HASH值相同,出现哈希碰撞,那么索引以链表的方式存储。InnoDB和MyISAM引擎都不支持哈希索引,它们的默认使用的是BTREE索引。但是可以通过伪哈希索引来实现,即增加一个存储HASH值的字段,并在HASH值上建立索引,在插入和更新的时候,建立触发器,自动添加计算后的HASH值到表里。这样在查询的时候,需要在WHERE子句手动指定使用哈希函数,唯一不足就是需要维护哈希值。
HASH索引检索效率非常高,索引的检索可以一次到位,不像BTREE索引需要从根节点到枝节点,最后才能访问到叶节点这样多次的I/O访问,所以HASH索引的查询效率要远高于BTREE索引。但是HASH索引在实际上并不会经常用到,是由于其特殊性并存在很多限制和弊端:
(1)HASH索引仅仅能满足“=”、“IN”和“<=>”(安全比较相等)查询,不能使用范围查询。因为HASH索引比较的是进行HASH运算后的HASH值,所以它只能用于等值的过滤,这里要注意经过HASH运算后的HASH值大小与运算前的大小关系不完全相同。
(2)优化器不能使用HASH索引来加速ORDER BY操作,即HASH索引无法被用来避免数据的排序操作。前面提到了HASH值的大小关系不一定与HASH运算前的大小关系完全一样,所以数据库无法利用HASH索引的数据来减少任何排序运算量。
(3)MySQL不能确定在两个HASH值之间大约有多少行。如果将一个MyISAM表改为HASH索引的MEMORY表,那么会影响一些查询的执行效率。
(4)只能使用整个关键字来搜索一行,即HASH索引不能利用部分索引键查询。对于组合索引,HASH索引是将组合索引键合并后再一起计算HASH值的,而不是单独计算HASH值,所以通过组合索引的前面一个或者几个索引键进行查询的时候,HASH索引无法被利用。
(5)HASH索引在任何时候都不能避免表扫描。HASH索引是将索引键通过HASH运算之后,将HASH值和所对应的行指针信息存放在一个HASH表中,由于不同索引键可能存在相同的HASH值,索引即使取满足某个HASh键值的数据的记录条数,也无法从HASH索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,从而得到相应的结果。
(6)HASH索引遇到大量的HASH值相等的情况后性能并不一定就比BTREE索引高。对于选择性比较低的索引键,如果创建HASH索引,那么将会存在大量记录指针信息存于同一个HASH值相关联。这样要定位某一条记录时就会非常麻烦,浪费多次表数据的访问,造成整体性能低下。
下面是创建HASH索引的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28mysql> CREATE TABLE TB_HASH(
-> id int not null,
-> name varchar(20) not null,
-> key using hash(name)
-> ) engine=MEMORY;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW CREATE TABLE TB_HASH;
+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------+
| TB_HASH | CREATE TABLE `TB_HASH` (
`id` int(11) NOT NULL,
`name` varchar(20) NOT NULL,
KEY `name` (`name`) USING HASH
) ENGINE=MEMORY DEFAULT CHARSET=utf8 |
+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SHOW INDEX FROM TB_HASH;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| TB_HASH | 1 | name | 1 | name | NULL | 0 | NULL | NULL | | HASH | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 esc)
mysql>
6. 什么是自适应哈希索引(Adaptive Hash Index)?
InnoDB引擎有一个特殊的功能称为自适应哈希索引。当InnoDB注意到某些索引值被使用频繁时,它会在内存中基于BTREE索引之上再创建一个HASH索引,这样就让BTREE索引也具有HASH索引的一些优点。例如:快速的HASH查找,这是一个全自动的内部的行为,用户无法控制或者配置。自适应哈希索引功能默认为开启,也可以根据需要进行关闭(即设置innodb_adaptive_hash_index=OFF,默认是ON)。
通过SHOW ENGINE INNODB STATUS命令可以看到当前自适应哈希索引的使用情况:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107mysql> SHOW ENGINE INNODB STATUS;
| Type | Name | Status | | InnoDB | |
=====================================
2020-11-23 15:07:44 0x7f1db80c4700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 32 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 73 srv_active, 0 srv_shutdown, 777794 srv_idle
srv_master_thread log flush and writes: 777867
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 2860
OS WAIT ARRAY INFO: signal count 1850
RW-shared spins 0, rounds 220, OS waits 110
RW-excl spins 0, rounds 0, OS waits 0
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 220.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx
------------
TRANSACTIONS
------------
Trx id counter 3011
Purge done for trx''s n:o < 3011 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421240615409504, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
290 OS file reads, 1253 OS file writes, 635 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 2918536
Log flushed up to 2918536
Pages flushed up to 2918536
Last checkpoint at 2918527
0 pending log flushes, 0 pending chkp writes
377 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 183650
Buffer pool size 8192
Free buffers 7762
Database pages 430
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 257, created 173, written 762
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 430, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=6984, Main thread ID=139765198345984, state: sleeping
Number of rows inserted 122, updated 40, deleted 0, read 580
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.00 sec)
mysql>
从上面的输出结果中,我们可以看到自适应哈希索引的使用信息,包括自适应哈希索引的大小、使用情况,每秒使用自适应索引搜索的情况。
7. 什么是前缀索引?
前缀索引,即对索引字段的前N个字符创建索引,这样可以极大缩小索引文件的大小,从而提高索引效率。当需要索引很长的字符列,这会让索引变得大且慢,此时就可以使用前缀索引。
前缀索引存在以下的缺点:在排序ORDER BY和分组GROUP BY操作时无法使用,也无法使用前缀索引做覆盖扫描,并且前缀索引降低了索引的可选择性。索引的可选择性是指不重复的索引值(也称基数)和数据表的记录总数(COUNT())的比值,范围为(0,1]。索引的可选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤更多的行,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
对于BLOB、TEXT或很长的VARCHAR类型**的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。使用前缀索引的诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便节约空间)。前缀应该足够长,以使得前缀索引的选择性接近于索引整个列的选择性,换句话说,前缀的“基数”应该接近于完整的列的“基数”。
下面以实际例子来看下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69# 首先创建一个city的表
mysql> CREATE TABLE TB_CITY(
-> id int auto_increment primary key,
-> city varchar(100) not null
-> );
Query OK, 0 rows affected (0.03 sec)
# 插入一些城市数据后的结果
mysql> SELECT * FROM TB_CITY;
+----+-----------------------------+
| id | city |
+----+-----------------------------+
| 1 | bejing, china |
| 2 | shanghai, china |
| 3 | guangzhou, guangdong, china |
| 4 | shenzhen, guangdong, china |
| 5 | wuhan, hubei, china |
| 6 | hangzhou, zhejiang, china |
| 7 | chongqing, china |
| 8 | nanjing, jiangsu, china |
| 9 | bejing, china |
| 10 | shanghai, china |
| 11 | guangzhou, guangdong, china |
| 12 | shenzhen, guangdong, china |
| 13 | wuhan, hubei, china |
| 14 | hangzhou, zhejiang, china |
| 15 | chongqing, china |
| 16 | nanjing, jiangsu, china |
| 17 | bejing, china |
| 18 | shanghai, china |
| 19 | guangzhou, guangdong, china |
| 20 | shenzhen, guangdong, china |
| 21 | wuhan, hubei, china |
| 22 | hangzhou, zhejiang, china |
| 23 | chongqing, china |
| 24 | nanjing, jiangsu, china |
| 25 | wuchang, hubei, china |
| 26 | nanchang, jiangxi, china |
| 27 | changsha, hunan, china |
| 28 | guilin, guangxi, china |
| 29 | haerbin, china |
| 30 | hainan, china |
+----+-----------------------------+
30 rows in set (0.00 sec)
# 查看完整列的可选择性
mysql> SELECT COUNT(DISTINCT city) / COUNT(*) FROM TB_CITY;
+---------------------------------+
| COUNT(DISTINCT city) / COUNT(*) |
+---------------------------------+
| 0.4667 |
+---------------------------------+
1 row in set (0.00 sec)
# 查看前缀2~6个字符的可选择性
mysql> SELECT COUNT(DISTINCT LEFT(city, 2)) / COUNT(*) as left2,
-> COUNT(DISTINCT LEFT(city, 3)) / COUNT(*) as left3,
-> COUNT(DISTINCT LEFT(city, 4)) / COUNT(*) as left4,
-> COUNT(DISTINCT LEFT(city, 5)) / COUNT(*) as left5,
-> COUNT(DISTINCT LEFT(city, 6)) / COUNT(*) as left6
-> FROM TB_CITY;
+--------+--------+--------+--------+--------+
| left2 | left3 | left4 | left5 | left6 |
+--------+--------+--------+--------+--------+
| 0.2333 | 0.4333 | 0.4667 | 0.4667 | 0.4667 |
+--------+--------+--------+--------+--------+
1 row in set (0.00 sec)
mysql>
从上面的结果可以看出,当索引前缀为4时的可选择性已经等于完整列的可选择性,所以我们可以在city列的前4个字符上创建前缀索引,如下:1
2
3
4
5
6
7
8
9
10
11
12mysql> ALTER TABLE TB_CITY ADD KEY (city(4));
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
# 在下面的结果中可以看到,正确使用了刚刚创建的索引
mysql> EXPLAIN SELECT * FROM TB_CITY WHERE city like 'ha%';
+----+-------------+---------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | TB_CITY | NULL | range | city | city | 14 | NULL | 5 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.04 sec)
8. 什么是全文(FULLTEXT)索引?
在索引上设置FULLTEXT参数后变为全文索引,全文索引只能创建在CHAR、VARCHAR或TEXT类型的字段上。通常在查询数据量较大的字符串类型的字段时,使用全文索引以提高查询速度。默认情况下,全文索引的搜索执行方式是不区分大小写的,但当索引的列使用二进制排序后,可以执行区分大小写的全文索引。
MySQL自带的全文索引只能用于MyISAM引擎的数据表,InnoDB引擎从5.6.4版本开始也支持全文索引,但是其他引擎就不支持全文索引了。此外,MySQL自带的全文索引只能对英文进行全文检索,如果要对包含中文的数据进行全文检索,需要采用Sphinx或Coreseek技术来处理中文。MySQL全文索引所能找到的默认最小长度为4个字符,由ft_min_word_len参数控制,如果查询字符串的长度过短,那么将无法得到期望的搜索结果。1
2
3
4
5
6
7
8
9mysql> SHOW VARIABLES LIKE '%ft_min_word_len%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| ft_min_word_len | 4 |
+-----------------+-------+
1 row in set (0.00 sec)
mysql>
在实际使用中,注意先创建表并插入所有数据后,再创建全文索引,而不要在创建表时就直接创建全文索引,因为前者比后者的全文索引效率更高。全文索引也存在以下的缺点:
(1)数据表越大,全文索引的效果好,但比较小的数据表会返回一些难以理解的结果。
(2)全文检索以整个单词作为匹配对象,单词变形(加上后缀或复数形式)就会被认为是另一个单词。
(3)只有由字母、数字、单引号、下划线构成的字符串会被认为是单词,带注音符号的字母仍是字母,例如“C++”就不再认为是单词。
(4)查询时不会区分大小写。
(5)只能在MyISAM表上使用,InnoDB表在5.6.4版本后也能使用。
(6)全文索引创建速度慢,而且对有全文索引的各种数据修改操作也慢。
8.1 创建全文索引
(1)创建表的同时创建全文索引1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33mysql> CREATE TABLE TB_ARTICLE(
-> id int auto_increment primary key,
-> title varchar(30),
-> content text,
-> FULLTEXT(title, content)
-> ) ENGINE=MYISAM;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW CREATE TABLE TB_ARTICLE;
+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| TB_ARTICLE | CREATE TABLE `TB_ARTICLE` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(30) DEFAULT NULL,
`content` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `title` (`title`,`content`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SHOW INDEX FROM TB_ARTICLE;
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| TB_ARTICLE | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| TB_ARTICLE | 1 | title | 1 | title | NULL | NULL | NULL | NULL | YES | FULLTEXT | | |
| TB_ARTICLE | 1 | title | 2 | content | NULL | NULL | NULL | NULL | YES | FULLTEXT | | |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
mysql>
(2)通过ALTER TABLE的方式来添加1
2
3
4# 在TB_NAME表的col_name列上创建一个名为index_name的全文索引
ALTER TABLE TB_NAME ADD FULLTEXT INDEX index_name ('col_name');
# 可以简写
ALTER TABLE TB_NAME ADD FULLTEXT index_name ('col_name');
(3)通过CREATE FULLTEXT INDEX的方式直接创建1
2
3CREATE FULLTEXT INDEX index_name ON TB_NAME ('col_name');
# 也可以创建全文索引时指定索引的长度
CREATE FULLTEXT INDEX index_name ON TB_NAME ('col_name'(10));
8.2 删除全文索引
(1)直接使用DROP INDEX:DROP INDEX index_name ON TB_NAME;1
2
3
4
5
6
7
8
9
10
11
12
13
14# 下面来看实际例子
mysql> DROP INDEX title ON TB_ARTICLE;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM TB_ARTICLE;
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| TB_ARTICLE | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
mysql>
(2)使用ALTER TABLE的方式:ALTER TABLE TB_NAME DROP INDEX index_name;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# 接着上面的例子,先添加一个名为article_index的全文索引
mysql> ALTER TABLE TB_ARTICLE ADD FULLTEXT article_index (title);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
# 查看索引是否创建成功
mysql> SHOW INDEX FROM TB_ARTICLE;
+------------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+------------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| TB_ARTICLE | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| TB_ARTICLE | 1 | article_index | 1 | title | NULL | NULL | NULL | NULL | YES | FULLTEXT | | |
+------------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
# 删除刚刚创建的全文索引
mysql> ALTER TABLE TB_ARTICLE DROP INDEX article_index;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
# 查看是否删除成功
mysql> SHOW INDEX FROM TB_ARTICLE;
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| TB_ARTICLE | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
mysql>
9. 什么是空间(SPATIAL)索引?
在索引上设置SPATIAL参数后变为空间索引,这个索引可以被用作地理数据支持。空间索引只能建立在空间数据类型上,这样可以提高系统获取空间数据的效率。MySQL中的空间数据类型包括GEOMETRY和POINT、LINESTRING和POLYGON等。目前只有MyISAM存储引擎支持空间索引,而且索引的字段不能为空值(注意InnoDB从5.7.5版本也开始支持)。下面来看个实际例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47mysql> CREATE TABLE TB_SPATIAL(
-> id int auto_increment primary key,
-> name varchar(100) not null,
-> pnt POINT not null,
-> SPATIAL INDEX (pnt)
-> ) ENGINE=MYISAM;
Query OK, 0 rows affected (0.00 sec)
mysql> DESC TB_SPATIAL;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(100) | NO | | NULL | |
| pnt | point | NO | MUL | NULL | |
+-------+--------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> SHOW INDEX FROM TB_SPATIAL;
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| TB_SPATIAL | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| TB_SPATIAL | 1 | pnt | 1 | pnt | A | NULL | 32 | NULL | | SPATIAL | | |
+------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
mysql> INSERT INTO TB_SPATIAL VALUES (NULL, 'test string', POINTFROMTEXT('POINT(15 20)'));
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> SELECT * FROM TB_SPATIAL;
+----+-------------+---------------------------+
| id | name | pnt |
+----+-------------+---------------------------+
| 1 | test string | .@ 4@ |
+----+-------------+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT name, ASTEXT(pnt) FROM TB_SPATIAL;
+-------------+--------------+
| name | ASTEXT(pnt) |
+-------------+--------------+
| test string | POINT(15 20) |
+-------------+--------------+
1 row in set, 1 warning (0.00 sec)
mysql>
10. 为什么索引没有被使用?
这是一个涉及面较广的问题,索引没有被使用有以下几种常见的场景:
(1)若索引出现了隐式类型转换(Implicit Type Conversion),则MySQL不会使用索引。例如,TB_USER表中的phone列是一个字符类型的索引列,如果在WHERE条件中使用了数值类型,那么不会使用索引。1
2
3
4# 下面的SQL语句不会使用索引
SELECT * FROM TB_USER WHERE phone=12345678901;
# 将WHERE条件中的数值类型改为字符类型,就能触发索引了
SELECT * FROM TB_USER WHERE phone='12345678901';
(2)在使用cast函数(用于将某种数据类型的表达式显式转换为另一种数据类型)时,如果字符集不同,则MySQL不会使用索引。
(3)如果WHERE条件中含有OR,并且OR条件中的列存在非索引列,则MySQL不会使用索引。
(4)对于多列索引(组合索引),若没有使用前导列,则MySQL不会使用索引(最左前缀匹配原则)。
(5)在WHERE子句中,如果索引列所对应的值的第一个字符由通配符(WILDCARD)开始,索引将不被采用,然而当通配符出现在字符串其他位置时,优化器就能利用索引。
(6)如果MySQL估计使用全表扫描要比使用索引快,那么将不使用索引。
(7)如果对索引字段进行函数、算术运算或其他表达式操作,那么MySQL也不使用索引。
...
...