一、前言
在前面的博客中已经讲过如何爬取静态网页(如政府网站)的内容,具体可点击此处查看。这里,笔者讲解下如何爬取动态网页上的内容,以爬取网易云音乐的榜单歌曲为例。
二、准备工作
本文主要使用Selenium模块 + 浏览器驱动webdriver来实现动态网页数据的爬取,因此需要做下面的准备工作。
1. 安装Selenium模块
这个比较简单,如果是Windows系统以管理员方式运行命令提示符,而若是Mac系统或者Linux系统只需要打开终端,然后执行下面的命令进行安装即可。1
pip install selenium
2. 安装浏览器驱动webdriver
Selenium的脚本可以控制浏览器进行操作,可以实现多个浏览器的调用,包括IE、Firefox、Safari、Google Chrome、Opera浏览器等。通过驱动浏览器执行特定的操作,能够更有效地爬取动态网页的内容。目前使用最多的浏览器莫过于Google Chrome浏览器和Firefox浏览器了。
如果是Google Chrome浏览器点击此处下载浏览器驱动,首先要按照提示选择与自己所用浏览器版本一致的ChromeDriver,如下图所示:
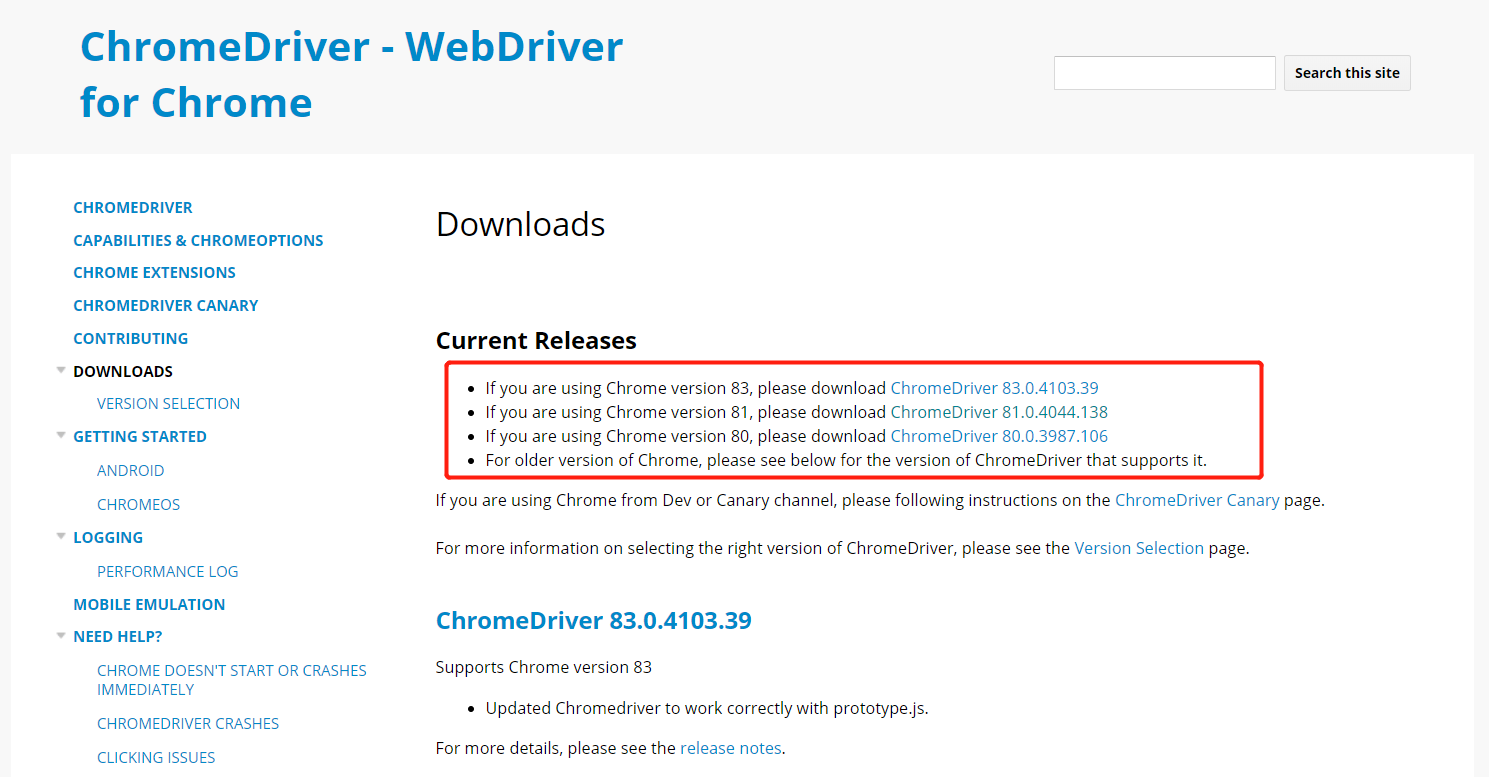
选择好版本后,点击进去选择与自己系统一致的下载即可。
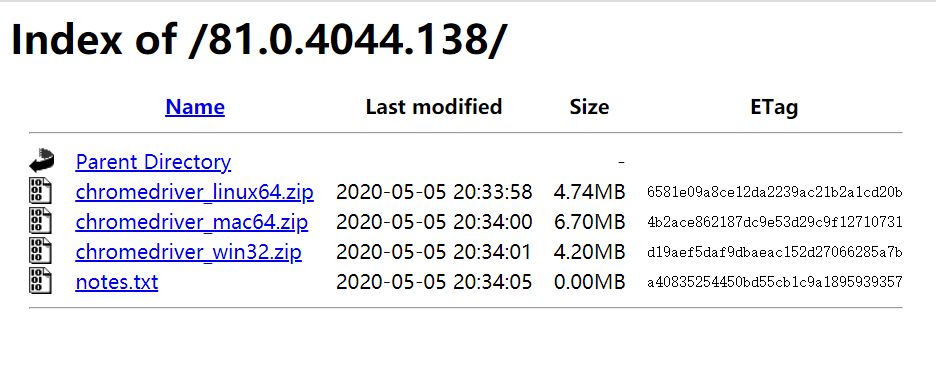
如果是Firefox浏览器点击此处下载浏览器驱动,这里只需要选择与自己系统一致的下载,如下图所示:
3. 移动浏览器驱动到Python Scripts目录
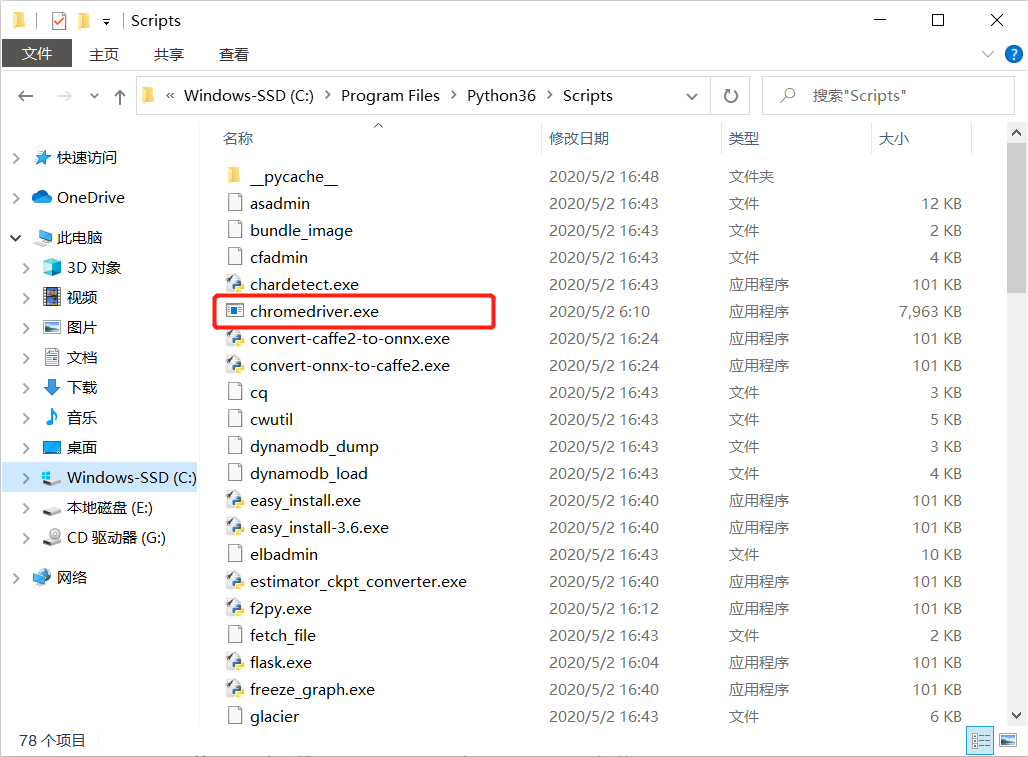
解压下载好的浏览器驱动包,并将它移动到Python安装目录的Scripts文件夹中,比如Windows系统上就移动到C:\Program Files\Python36\Scripts,移动成功后如下图所示:
三、爬取榜单歌曲
关于网易云音乐的所有榜单点击此处前往观看,这里选用了网易云音乐以下几个榜单:
'云音乐飙升榜': 'https://music.163.com/#/discover/toplist?id=19723756'
'云音乐新歌榜': 'https://music.163.com/#/discover/toplist?id=3779629'
'网易原创歌曲榜': 'https://music.163.com/#/discover/toplist?id=2884035'
'云音乐热歌榜': 'https://music.163.com/#/discover/toplist?id=3778678'
爬取之前需要定位歌曲列表位置,在浏览器中右键审查元素可以看到,所有歌曲在//div[@id="song-list-pre-cache"]//table[@class="m-table m-table-rank"]/tbody标签中。每一首歌曲对应一个tr标签,歌曲名称在//tr//span[@class="txt"]/a/b标签的title属性中,歌曲URL在//tr//span[@class="txt"]/a标签的 href属性中,歌手名字在//tr//div[@class="text"]/span的title属性中。
弄清楚这些要爬取的信息后,就可以进行信息爬取了,这里分享两种方法。
1. 使用selenium爬取歌曲信息
这种方法就是完全使用selenium来操作动态网页,获取上面提到的对应的标签值,从而实现数据的爬取。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43def crawl_163music1():
url_dict = {
'云音乐飙升榜': 'https://music.163.com/#/discover/toplist?id=19723756',
'云音乐新歌榜': 'https://music.163.com/#/discover/toplist?id=3779629',
'网易原创歌曲榜': 'https://music.163.com/#/discover/toplist?id=2884035',
'云音乐热歌榜': 'https://music.163.com/#/discover/toplist?id=3778678'
}
songs_dict = {}
count = 0
# 遍历要爬取的榜单
for key, value in url_dict.items():
brower = webdriver.Chrome()
# 加载页面
brower.get(value)
# 切换到 iframe
brower.switch_to.frame('contentFrame')
# 定位歌曲列表
song_list_pre = brower.find_element_by_id('song-list-pre-cache')
song_table = song_list_pre.find_element_by_tag_name('tbody')
# 注意此处定位的是所有tag为tr的elements,即所有歌曲
song_rows = song_table.find_elements_by_tag_name('tr')
songs_list = []
for i in range(len(song_rows)):
span = song_rows[i].find_element_by_class_name('txt')
# 使用相对路径获取 url 和 name
url = span.find_element_by_xpath('./a').get_attribute('href')
name = span.find_element_by_xpath('./a/b').get_attribute('title')
singer = song_rows[i].find_element_by_class_name('text').get_attribute('title')
songs_list.append({
'name': name,
'url': url,
'singer': singer,
})
songs_dict[key] = songs_list
count += len(songs_list)
print('Crawl ' + str(len(songs_list)) + ' songs from ' + value)
del songs_list
# 处理完一个网页后间隔一会,不然IP会被禁
time.sleep(5)
# 保存歌曲信息到json文件
write_json_file('songs2.json', songs_dict)
print('******** Total: ' + str(count) + ' songs are saved! ********')
2. 使用selenium + etree爬取歌曲信息
第二种方法是先通过selenium获取动态页面的源码,然后使用静态页面爬取的方法,即使用xpath来解析所需要的标签值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42def crawl_163music2():
url_dict = {
'云音乐飙升榜': 'https://music.163.com/#/discover/toplist?id=19723756',
'云音乐新歌榜': 'https://music.163.com/#/discover/toplist?id=3779629',
'网易原创歌曲榜': 'https://music.163.com/#/discover/toplist?id=2884035',
'云音乐热歌榜': 'https://music.163.com/#/discover/toplist?id=3778678'
}
songs_dict = {}
count = 0
# 遍历要爬取的榜单
for key, value in url_dict.items():
brower = webdriver.Chrome()
# 加载页面
brower.get(value)
# 切换到 iframe
brower.switch_to.frame('contentFrame')
# etree解析HTML标签
html = etree.HTML(brower.page_source)
# 提取歌曲名
song_names = html.xpath('//div[@id="song-list-pre-cache"]//table//tr//span[@class="txt"]/a/b/@title')
# 提取歌曲URL
song_urls = html.xpath('//div[@id="song-list-pre-cache"]//table//tr//span[@class="txt"]/a/@href')
song_urls = list(map(lambda x: 'https://music.163.com' + x, song_urls))
# 提取歌手名
song_singers = html.xpath('//div[@id="song-list-pre-cache"]//table//tr//div[@class="text"]/span/@title')
songs_list = []
for i in range(len(song_names)):
songs_list.append({
'name': song_names[i],
'url': song_urls[i],
'singer': song_singers[i],
})
songs_dict[key] = songs_list
count += len(songs_list)
print('Crawl ' + str(len(songs_list)) + ' songs from ' + value)
del songs_list
# 处理完一个网页后间隔一会,不然IP会被禁
time.sleep(5)
# 保存歌曲信息到json文件
write_json_file('songs1.json', songs_dict)
print('******** Total: ' + str(count) + ' songs are saved! ********')
3. 保存歌曲信息到json文件
爬取到歌曲信息后,可自行存储到数据库,也可以保存到TXT文件或者JSON文件。笔者这里是保存到JSON文件,保存JSON文件的代码实现如下:1
2
3
4
5
6
7
8
9
10def write_json_file(filename, data):
"""
write data to json file
:param filename: json filename, like '/path/filename.json'
:param data: data for writing, any type
"""
fp = open(filename, mode='w', encoding='utf-8')
# ensure_ascii=False 防止乱码
json.dump(data, fp, ensure_ascii=False)
fp.close()
最终保存为JSON文件后的结果如下图所示:

...
...